Documentation
Read an introductory tutorial. Browse the complete Mars language reference, or the library reference.

Downloads
Get started with Mars (Linux only). Download the compiler, in source or binary form, and begin building your own Mars programs.
About Mars
Mars is a very simple imperative programming language with a catch: all of the functions and expressions are pure.
That means when you call a function, it is guaranteed to have no side-effects: it can't mutate its arguments, modify global variables, or perform input/output. But unlike other pure languages, Mars gives you all the nice features of imperative programming, like local variable assignments and loops. The compiler also automatically converts inefficient copy-and-update operations into in-place destructive operations.
Mars also has some other nice features borrowed from functional programming: a strong static type system, algebraic data types, pattern-matching switch statements, and higher-order functions.
Mars is an experiment, not a full-featured programming language. You can use it for playing with the boundaries between imperative and declarative programming, but we don't recommend you write real software with it.

Downloads
Version 1.0
- Debian/Ubuntu binary package (64-bit).
- To install, type:
sudo dpkg -i mars_1.0.0-1_amd64.deb. - To uninstall, type:
sudo apt-get remove mars.
- To install, type:
- Source tarball (requires Mercury).
- Old versions.
- Browse the Bazaar Repository
- To check out locally, type:
bzr branch lp:mars.
- To check out locally, type:
- Vim syntax file.
Sample programs
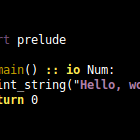
Simple Mars programs look a lot like Python:
import prelude
def main() :: io Num:
print_string("Hello, world!\n")
return 0But Mars is statically typed, and forbids side-effects (other than input/output effects, in functions specially annotated with io, as seen here).
For example, when you call array_concat, you concatenate two strings, without modifying either of them (just like + in Python):
hello = "Hello"
return array_concat(hello, " world")However, Mars is smart enough to realise that you won't be using hello again, so automatically reuses the memory for that string, instead of copying it.
Learn how to write Mars with the tutorial, or learn about the automatic memory reuse system.
Here are several complete Mars programs. These are all included in the source distribution, under samples.
All samples on this site are in the public domain.